Query fan-out : quand l'IA générative décompose vos questions

Les IA génératives ne se contentent plus de chercher une réponse unique. Face à un prompt, elles décomposent désormais chaque question en plusieurs sous-requêtes lancées en parallèle avant de synthétiser les résultats. Ce mécanisme s'appelle le query fan-out, et il redéfinit les règles de visibilité en ligne.
Résumé de l’article
- Le query fan-out est un processus de décomposition d'une requête en sous-requêtes multiples, utilisé par l'ensemble des IA génératives dotées d'un accès web (ChatGPT, Perplexity, Gemini) pour construire des réponses plus complètes.
- Les IA génératives utilisent trois modes de réponse : la réponse directe (sans recherche externe), le fan-out/fan-in (décomposition puis agrégation), et le chain of thought (raisonnement séquentiel).
- Cette logique transforme la stratégie de contenu : la couverture thématique prime sur le ciblage d'un mot-clé unique, et l'autorité éditoriale devient un critère de sélection déterminant.
- Pour structurer ses contenus, il faut simuler le fan-out pour identifier les angles manquants, auditer la couverture existante et optimiser la présence on-site et off-site.
- Mesurer sa visibilité dans les LLM repose sur deux signaux complémentaires : l'analyse des logs serveur pour comprendre comment les IA crawlent votre site, et le suivi de prompts pour mesurer si votre marque apparaît dans les réponses générées.
Un mécanisme au cœur des IA génératives
Fan-in, fan-out : les deux faces d'un même processus
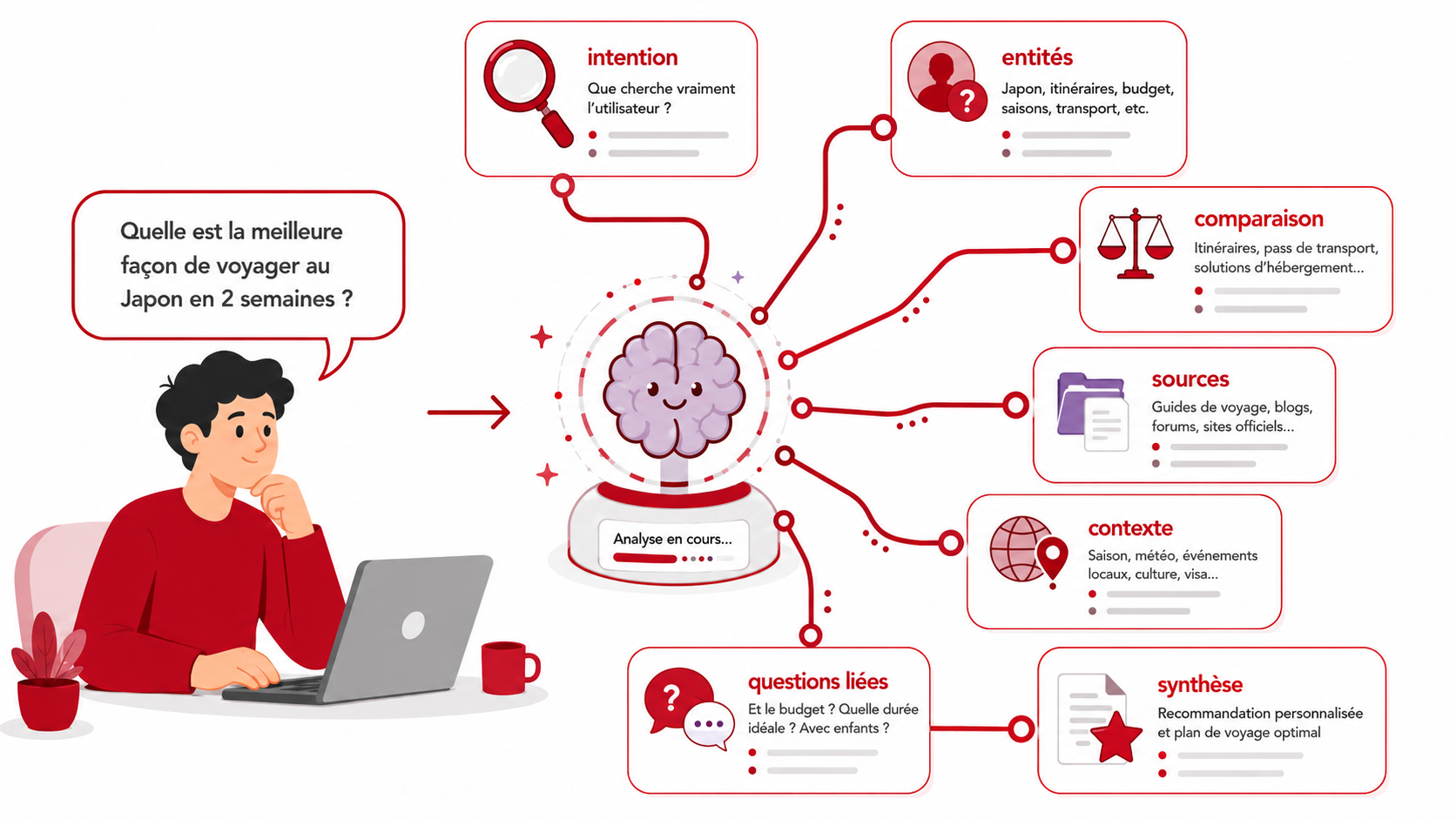
Le query fan-out désigne la phase où une IA générative décompose une requête complexe en plusieurs sous-requêtes traitées simultanément. Chaque sous-requête interroge des sources distinctes, des bases de données ou des fragments d'information disponibles en ligne.
Le fan-in constitue la phase complémentaire. Il s'agit de l'agrégation des résultats collectés lors du fan-out, suivie de leur synthèse en une réponse unique et cohérente. Les deux mécanismes fonctionnent en tandem : le fan-out distribue la charge de recherche, le fan-in recompose l'information.
Query fan-out SEO vs fan-out électronique / VLSI : deux notions à ne pas confondre
En électronique et en conception de circuits intégrés (VLSI), le fan-out mesure le nombre maximal d'entrées de portes logiques qu'une sortie peut alimenter sans dégradation du signal. Cette définition est purement matérielle et n'a aucun lien avec le traitement des requêtes par les IA.
Dans les systèmes distribués, le fan-out désigne un pattern de diffusion de messages vers plusieurs consommateurs. Des technologies comme Kafka ou les modèles pub/sub utilisent ce principe pour router un flux de données vers de multiples destinations en parallèle. Cette logique partage avec le query fan-out IA l'idée de parallélisation, mais elle s'applique à la distribution de messages, non à la décomposition sémantique d'une requête.
Comment l'IA traite un prompt : les 3 modes de réponse
Face à un prompt, les IA génératives ne réagissent pas toutes de la même manière. On peut identifier trois grands modes de traitement, chacun correspondant à un niveau de complexité différent de la requête.
La réponse directe
Dans ce mode, le LLM puise directement dans ses connaissances internes pour fournir une réponse immédiate, sans recourir à des sources externes ni à des bases de données en temps réel.
Ce fonctionnement s'applique aux questions factuelles simples, dont la réponse fait partie des données d'entraînement du modèle. "Quelle est la capitale de la France ?" ou "Qu'est-ce que le RGPD ?" en sont des exemples typiques.
Le fan-out / fan-in : décomposer pour mieux synthétiser
Lorsque la requête devient plus complexe ou nécessite une couverture thématique élargie, l'IA active le mécanisme de fan-out. Elle décompose le prompt en plusieurs sous-requêtes lancées en parallèle, collecte des fragments d'information depuis des sources web, des index et des bases de données, puis agrège l'ensemble en une réponse synthétique lors de la phase de fan-in.
Exemple concret : un utilisateur demande "Quelle est la meilleure stratégie SEO pour un e-commerce ?". L'IA peut générer plusieurs sous-requêtes en parallèle avant de synthétiser une réponse unique :
- "optimisation des fiches produits SEO",
- "netlinking e-commerce",
- "données structurées produits",
- "vitesse de chargement site marchand".
Le chain of thought : raisonner étape par étape
Le chain of thought repose sur un raisonnement séquentiel où l'IA décompose le problème en étapes successives, chacune s'appuyant sur la précédente. Contrairement au fan-out qui fonctionne en parallèle, le chain of thought avance de manière linéaire.
Ce mode est particulièrement efficace pour les tâches de raisonnement complexe, les calculs ou les analyses logiques. Certains prompts peuvent d'ailleurs combiner les deux approches : un fan-out pour rassembler des sources variées, puis un chain of thought pour structurer le raisonnement final.
|
Mode de réponse |
Principe |
Type de requête concernée |
Exemple |
|
Réponse directe |
Puise dans les connaissances internes du LLM |
Questions factuelles simples |
"Qu'est-ce que le RGPD ?" |
|
Fan-out / fan-in |
Décompose en sous-requêtes parallèles, agrège les résultats |
Questions complexes nécessitant plusieurs sources |
"Meilleure stratégie SEO pour un e-commerce" |
|
Chain of thought |
Raisonnement séquentiel |
Tâches de raisonnement, calculs, analyses logiques |
"Calculer le ROI d'une campagne Paid Media sur 6 mois" |
ChatGPT, Perplexity, Gemini : comment chacun l'implémente
Les grandes plateformes génératives utilisent le fan-out, mais avec des implémentations et des niveaux de transparence différents. Ces différences influencent directement la manière dont les marques peuvent analyser et optimiser leur visibilité.
ChatGPT : du prompt à plusieurs sous-requêtes web en parallèle
Lorsque ChatGPT active sa fonctionnalité de recherche web, il décompose le prompt initial en plusieurs sous-requêtes ciblées qu'il envoie simultanément à ses partenaires de recherche. L'utilisateur peut parfois observer ces sous-requêtes dans l'interface, notamment lorsque ChatGPT affiche les sources consultées.
Cette visibilité reste partielle et dépend du type de requête et de la version utilisée (gratuite, Plus, Pro).
Perplexity : le moteur le plus transparent sur ses sources
Perplexity affiche explicitement les sources consultées et les citations numérotées pour chaque réponse générée. Cette transparence en fait la plateforme la plus lisible pour observer le fan-out en action.
Le système Sonar, basé sur Llama de Meta, intègre la recherche web en temps réel et présente les résultats sous forme de réponse structurée avec références.
Gemini : une logique alignée avec les standards des IA génératives
Du côté de Gemini, la logique est similaire à celle observée sur ChatGPT et Perplexity, mais avec une intégration plus forte à l'écosystème Google (Search, Knowledge Graph, etc.). Le modèle décompose également les requêtes complexes en sous-thématiques pour explorer plusieurs angles en parallèle avant de produire une réponse synthétique.
Avec une moyenne de 10 sous-requêtes par prompt, Gemini est le moteur qui déploie le fan-out le plus large.
La différence ne réside donc pas tant dans le mécanisme que dans son environnement d'exécution. Là où Perplexity maximise la transparence des sources et où ChatGPT expose partiellement ses recherches, Gemini s'appuie davantage sur ses propres infrastructures (index, données structurées, graphes de connaissances) pour alimenter ses réponses.
|
Plateforme |
Visibilité du fan-out |
Sources |
Spécificités |
|
ChatGPT |
Partielle (selon version) |
Oui, avec citations cliquables |
Sous-requêtes parfois visibles dans l'interface |
|
Perplexity |
Élevée |
Oui, citations numérotées systématiques |
Plateforme la plus transparente sur la décomposition |
|
Gemini |
Limitée |
Oui, liens vers sources |
Intégration avec graphes de connaissances Google |
Ce que le fan-out change pour votre stratégie de contenu
La fin du "une page, une requête"
Le query fan-out rend obsolète l'approche classique qui consistait à cibler un mot-clé principal par page. Lorsqu'une IA décompose un prompt en plusieurs sous-requêtes parallèles, elle puise l'information dans différentes pages de votre site, voire de sites concurrents, pour synthétiser sa réponse.
La logique de couverture thématique globale prime désormais sur le positionnement page par page. L'IA recompose l'information à partir de multiples sources, ce qui signifie que votre capacité à traiter un sujet sous plusieurs angles détermine votre présence dans les réponses générées.
La couverture thématique prime sur la longueur
Dans un contexte où les IA agrègent des fragments d'information provenant de plusieurs pages, la profondeur et l'exhaustivité du traitement d'un sujet comptent davantage que la longueur brute d'un article. Un contenu de 800 mots qui répond précisément à une sous-requête peut être préféré à un guide de 3 000 mots qui survole plusieurs aspects sans les approfondir.
Le clustering thématique devient une approche adaptée pour structurer cette couverture. Il s'agit de regrouper des mots-clés et des intentions de recherche connexes autour de pages piliers, puis de produire des contenus satellites qui approfondissent chaque angle. Cette architecture permet de répondre efficacement aux multiples sous-requêtes générées par le fan-out.
EEAT et notoriété off-site : plus critiques que jamais
Les signaux d'autorité, d'expertise, d'expérience et de fiabilité (EEAT) deviennent encore plus déterminants lorsque l'IA sélectionne ses sources. Face à plusieurs contenus traitant d'une même sous-requête, les moteurs génératifs privilégient ceux qui émanent de sources reconnues, citées par des tiers et dotées d'une notoriété établie.
Les citations externes, les mentions de marque sur des sites tiers et le netlinking renforcent cette autorité perçue. Un contenu publié sur un site à faible autorité, même techniquement bien optimisé, aura moins de chances d'être extrait par l'IA qu'un contenu équivalent provenant d'une source reconnue dans sa thématique.
Comment structurer ses contenus pour être extrait par les IA
Simuler le fan-out pour identifier les angles manquants
Utiliser les IA elles-mêmes pour anticiper leur fonctionnement constitue une approche pragmatique et directement opérationnelle. Il s'agit de soumettre vos requêtes cibles à ChatGPT, Perplexity ou Gemini, puis d'observer quelles sous-requêtes sont générées.
Une fois ces sous-requêtes identifiées, vous pouvez les croiser avec vos pages existantes pour repérer les angles non couverts.
Auditer vos contenus existants
L'audit de contenu ne consiste plus à vérifier page par page si un mot-clé est présent, mais à évaluer si l'ensemble de vos contenus répond aux sous-requêtes identifiées lors de la phase de simulation.
L'approche par cluster thématique s'impose ici. Plutôt que d'analyser chaque URL isolément, regroupez vos contenus par sujet ou intention de recherche. Vérifiez ensuite si chaque cluster couvre l'ensemble des facettes attendues par les IA.
Produire et optimiser on-site et off-site
La production de contenus optimisés pour le fan-out repose sur des principes clairs et applicables immédiatement :
- Titres clairs et explicites : chaque H2 ou H3 doit formuler une question ou un angle précis, facilitant l'extraction par les IA.
- Réponses directes en début de paragraphe : placez l'information essentielle dès les premières phrases, avant de développer.
- Paragraphes courts et structurés : privilégiez des blocs de 3 à 5 phrases, avec une idée par paragraphe.
- Données structurées schema.org : balisez vos contenus avec les schémas Article, FAQPage, Organization ou Product pour aider les IA à comprendre la nature de vos informations.
- Travail off-site : les citations externes, mentions de marque et liens entrants renforcent votre autorité thématique, critère déterminant dans la sélection des sources par les IA.
Mesurer sa visibilité dans les LLM : passer d'une logique d'outil à une logique d'observation
Mesurer sa présence dans les réponses générées par les IA ne peut pas reposer uniquement sur des outils tiers. Contrairement au SEO, il n'existe pas d'interface centralisée permettant de suivre ses performances. L'enjeu consiste donc à reconstruire cette visibilité à partir des interactions réelles avec les modèles.
Chez SYNERWEB, l'approche repose sur l'analyse croisée de deux signaux complémentaires :
- Les logs serveur : identifier quelles IA crawlent votre site, quelles pages elles sollicitent et comment cette activité évolue dans le temps.
- Le suivi de prompts : analyser les requêtes formulées par les utilisateurs dans les interfaces IA pour mesurer si votre marque apparaît dans les réponses, dans quel contexte et sur quels angles.
Cette approche permet de dépasser une simple logique de "ranking" pour entrer dans une logique de contribution informationnelle : comprendre si vos contenus alimentent réellement les réponses des IA.
FAQ
Quelle est la définition du query fan-out ?
Le query fan-out désigne le mécanisme par lequel une IA générative décompose une requête utilisateur en plusieurs sous-requêtes parallèles avant de synthétiser une réponse unique. Lorsqu'un utilisateur pose une question complexe, le système lance simultanément plusieurs recherches ciblées sur différents aspects du sujet. Les résultats collectés sont ensuite agrégés et reformulés en une réponse cohérente.
Quelle est la différence entre fan-out et fan-in ?
Le fan-out et le fan-in représentent deux phases complémentaires d'un même processus. Le fan-out correspond à la phase d'expansion : l'IA décompose la requête en plusieurs sous-requêtes lancées en parallèle. Le fan-in désigne la phase d'agrégation : le système rassemble, filtre et synthétise les résultats obtenus pour produire une réponse unique. Ces deux étapes fonctionnent systématiquement ensemble.
ChatGPT utilise-t-il vraiment le query fan-out ?
Oui, ChatGPT utilise le query fan-out lorsqu'il active sa fonctionnalité de recherche web pour répondre à des questions nécessitant des informations actualisées. L'utilisateur peut parfois observer les sous-requêtes générées s'afficher dans l'interface pendant la phase de recherche. ChatGPT décompose le prompt initial en plusieurs questions parallèles, collecte les résultats, puis agrège ces informations pour produire une réponse synthétique.
Existe-t-il des extensions pour recenser toutes les query fan-out ?
Oui, il existe des outils permettant de visualiser les sous-requêtes générées par les moteurs d'IA lors de la phase de fan-out. Ces solutions affichent les différentes recherches parallèles lancées par le système. Cependant, environ 27 % seulement des sous-requêtes restent identiques lors de recherches répétées sur le même prompt, ce qui rend la mesure plus complexe qu'en SEO traditionnel.
Être en top 10 Google garantit-il d'apparaître dans les réponses IA ?
Non, un bon classement dans les résultats organiques Google ne garantit pas toujours l'apparition dans les réponses générées par les IA. Les critères de sélection des moteurs génératifs privilégient l'autorité thématique globale, la couverture exhaustive d'un sujet et la capacité à répondre précisément aux sous-requêtes. Un site peut donc être bien positionné sur un mot-clé spécifique sans être cité dans une réponse IA, et inversement.
Fan-out, RAG, GEO : quelles différences ?
Ces trois concepts appartiennent à des niveaux différents. Le query fan-out est un mécanisme technique de décomposition et d'agrégation des requêtes. Le RAG (Retrieval-Augmented Generation) désigne une architecture logicielle permettant aux modèles de langage de récupérer des informations externes, souvent via des graphes de connaissances. Le GEO (Generative Engine Optimization) est une discipline d'optimisation visant à structurer les contenus pour améliorer la visibilité dans les réponses IA.
Besoin d'évaluer votre visibilité dans les moteurs IA et d'optimiser votre présence dans les réponses génératives ?
Chez SYNERWEB, nous accompagnons les ETI et grands comptes dans le déploiement de stratégies GEO data-driven, en croisant audit de visibilité, optimisation de contenu et suivi de performance.
Contactez nos experts SEO pour analyser votre écosystème et identifier les leviers prioritaires.


